Seitentrennung mit Embedded Documents erscheint rein technisch gesehen als ein einfaches Thema.
Kompliziert wird es, wenn man fachlich definieren möchte, was sich jeder einzelne im konkreten Fall unter dem Splitting von PDFs vorstellt bzw. im Projekt umsetzen möchte:
- Wohin soll die X neuen Dokumente gesplittet werden?
- In den gleichen Ordner?
- Weil es Eingangsbestellungen sind ist X Auftragsordner mit dem gleichen Datum, welche gleich mit angelegt werden müssen?
- Weil es Eingangspost ist in X Post-Workflows?
- …
- Was passiert mit dem Original?
- Bleibt es das erste Dokument, weil es eines unter vielen ist?
- Ist es ein wichtiges Original und muss separat aufbewahrt werden?
- Soll es gelöscht werden?
- …
- Beziehung zwischen den Dokumenten: Sollen die ehemals zusammengesetzten und nun gesplittteten X Dokumente in enaio®/yuuvis® verknüpft bleiben? Wenn ja, wie?
- Über Metadaten (gleicher Schlüssel, welcher generiert werden muss, im Feld „Splitting“ o. ä.)
- Über Notizverknüpfungen
- …
- Wie ergeben sich die Metadaten der neuen Teilbelege?
- Alle gleich?
- Alle gleich, aber es wird ine einem konkreten Feld passend zur Objektdefinition durchgezählt?
- OCR des Barcodes pro erster Seite?
- …
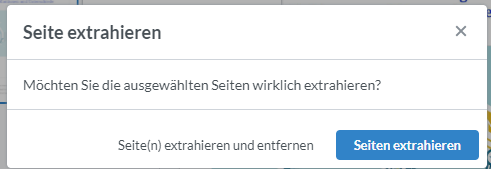
Selbstverständlich muss es nicht kompliziert sein. Zusammen mit Komm.ONE haben wir eine beispielhafte Umsetzung geschaffen, welche es Ihnen erlaubt Dokumente über die Seitenleiste zu splitten:
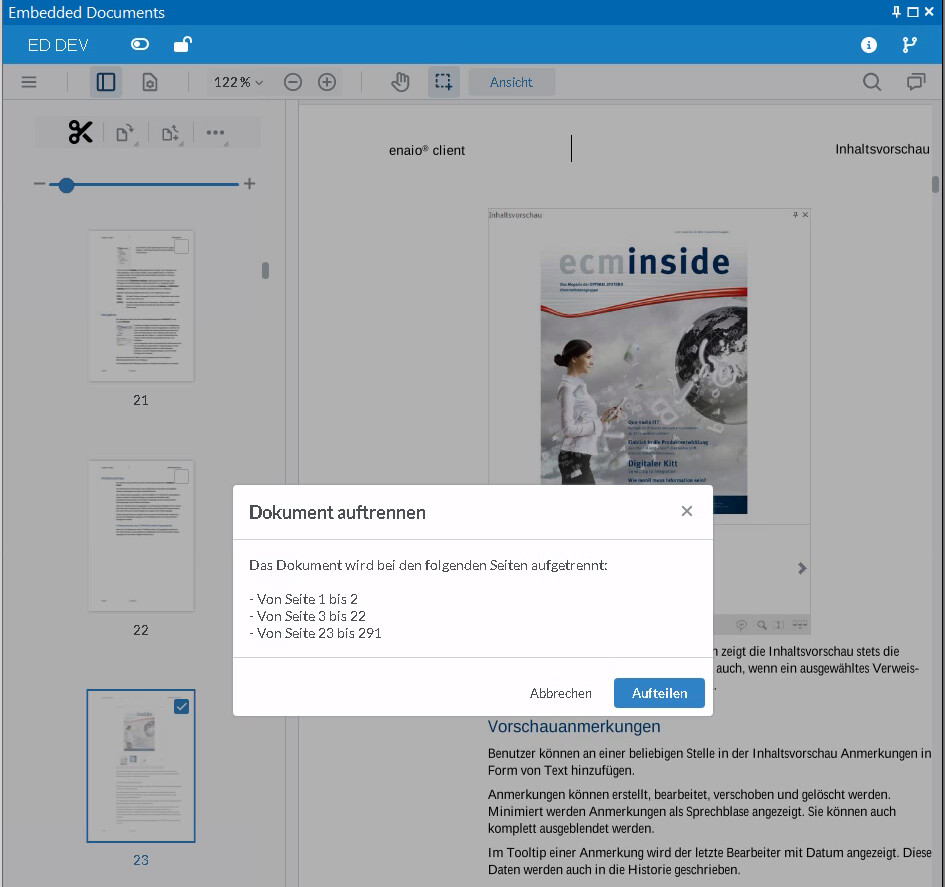
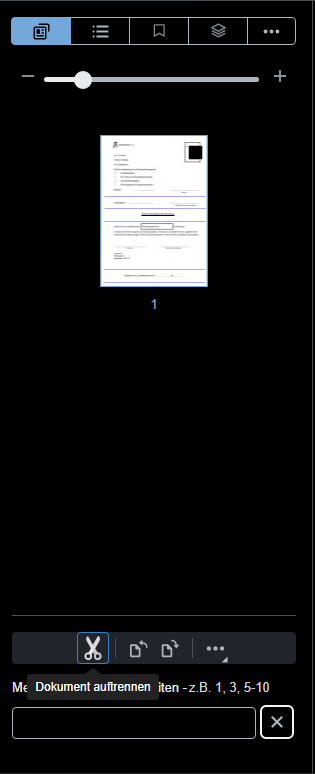
In unserem Beispiel-Interceptor können die User Checkboxen auf den jeweils neuen ersten Seiten eines jeden Teilbelegs setzen und drücken zum Aufteilen das Scheren-Symbol.
Beispiel-Code
Der Interceptor kann individuell angepasst und bei Bedarf wie gewohnt in .-.\service-manager\data\ed\public\interceptors abgelegt werden.
Hinweis: In diesem Fall werden gesplittete Seiten direkt neben dem aktuellen Dokument ohne spezielle Verschlagwortung abgelegt. Ein weiterentwickelte und für Baden-Württemberg standardisierte Version davon stellt der enaio®- und yuuvis®-Partner Komm.ONE ihren Kunden bereit.
Alle anderen können sich im Projekt anhand dieses Beispieles Anregungen holen:
let currentInfo = null;
let currentViewer = null;
let extractPagesInterceptor = {
initEditorConfiguration(instance, config) {
let { documentViewer, annotationManager } = instance.Core;
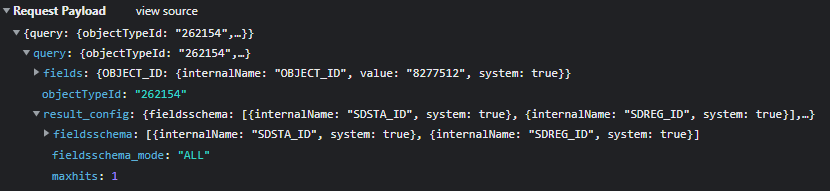
let getMetadata = async (typeId, id) => {
let request = {
query: {
objectTypeId: typeId,
fields: {
OBJECT_ID: {
internalName: 'OBJECT_ID',
value: id,
system: true,
},
},
result_config: {
fieldsschema: [
{
internalName: 'SDSTA_ID',
system: true,
},
{
internalName: 'SDREG_ID',
system: true,
},
],
fieldsschema_mode: 'ALL',
maxhits: 1,
},
},
};
const rawResponse = await fetch(`/api/dms/objects/search/native`, {
method: 'POST',
headers: {
Accept: 'application/json',
'Content-Type': 'application/json',
},
body: JSON.stringify(request),
});
let result = await rawResponse.json();
return result.objects[0];
};
let insert = async (properties, blob) => {
let data = {
objects: [
{
properties: properties,
contentStreams: [
{
mimeType: 'application/pdf',
fileName: 'content.pdf',
cid: 'cid_1',
},
],
},
],
};
const formData = new FormData();
formData.append('data', new Blob([JSON.stringify(data)], { type: 'application/json' }), 'data.json');
formData.append('cid_1', blob, 'content.pdf');
const rawResponse = await fetch(`/api/dms/objects`, {
method: 'POST',
headers: {
Accept: 'application/json',
},
body: formData,
});
return await rawResponse.json();
};
let confirm = (ranges) => {
return new Promise(async (resolve, reject) => {
let ui = instance.UI;
let message = 'Das Dokument wird bei den folgenden Seiten aufgetrennt: \r\n\r\n';
for (let range of ranges) {
message += `- Von Seite ${range.start} bis ${range.end}\r\n`;
}
let result = await ui.showWarningMessage({
title: 'Dokument auftrennen',
message: message,
confirmBtnText: 'Aufteilen',
secondaryBtnText: 'Abbrechen',
onConfirm: async () => {
resolve(true);
},
onSecondary: async () => {
resolve(false);
},
onCancel: () => {
resolve(false);
},
});
});
};
let success = (ranges) => {
return new Promise(async (resolve, reject) => {
let ui = instance.UI;
let message = 'Das Dokument wurde erfolgreich aufgetrennt';
let result = await ui.showWarningMessage({
title: 'Auftrennung abgeschlossen',
message: message,
confirmBtnText: 'ok',
onConfirm: async () => {
resolve(true);
},
onCancel: () => {
resolve(false);
},
});
});
};
let extract = (from, to) => {
return new Promise(async (resolve, reject) => {
let doc = documentViewer.getDocument();
let pagesToExtract = [];
for (let i = from; i <= to; i++) {
pagesToExtract.push(i);
}
let annotList = annotationManager.getAnnotationsList().filter((annot) => pagesToExtract.indexOf(annot.PageNumber) > -1);
let xfdfString = await annotationManager.exportAnnotations({ annotList });
let data = await doc.extractPages(pagesToExtract, xfdfString);
let arr = new Uint8Array(data);
let blob = new Blob([arr], { type: 'application/pdf' });
resolve(blob);
});
};
let pad = (num, places) => {
return String(num).padStart(places, '0');
};
let onClick = async (selectedPageNumbers) => {
if (selectedPageNumbers.length < 2) {
instance.UI.showErrorMessage("Selectieren Sie mindestens zwei Seiten");
return;
}
let pageCount = documentViewer.getPageCount();
let ranges = [];
for (let i = 0; i < selectedPageNumbers.length; i++) {
let start = selectedPageNumbers[i];
let end = selectedPageNumbers.length > i + 1 ? selectedPageNumbers[i + 1] - 1 : pageCount;
ranges.push({ start: start, end: end });
}
let result = await confirm(ranges);
if (!result) {
return;
}
let sourceMetadata = await getMetadata(currentInfo.typeId, currentInfo.id);
for (range of ranges) {
let blob = await extract(range.start, range.end);
let parentId = sourceMetadata.properties['system:SDREG_ID'].value != "0" ? sourceMetadata.properties['system:SDREG_ID'].value : sourceMetadata.properties['system:SDSTA_ID'].value;
let properties = {
'system:parentId': {
value: parentId,
},
'system:objectTypeId': {
value: currentInfo.typeId
},
//Name: { value: sourceMetadata.properties.Name.value + ' ' + pad(range.start, 4) + ' - ' + pad(range.end, 4) },
//Type: { value: sourceMetadata.properties.Type.value },
};
for(let name of Object.keys(sourceMetadata.properties)){
if(!name.startsWith("system:")){
properties[name] = sourceMetadata.properties[name];
}
}
await insert(properties, blob);
}
await success(ranges);
};
let buttons = [
{
type: 'customPageOperation',
header: 'enaio',
dataElement: 'customPageOperations',
operations: [
{
title: 'Dokument auftrennen',
img: '../../interceptors/scissors-solid.svg',
onClick: async (selectedPageNumbers) => {
await onClick(selectedPageNumbers);
},
dataElement: 'customPageOperationButton',
},
],
},
{ type: 'divider' },
];
//instance.UI.pageManipulationOverlay.add(buttons);
instance.UI.multiPageManipulationControls.add(buttons);
},
async updateEditorConfiguration(instance, info, config, viewer) {
currentInfo = info;
currentViewer = viewer;
console.log('set currentInfo');
instance.UI.enableElements(['thumbnailControl', 'documentControl']);
instance.UI.enableFeatures(['ThumbnailMultiselect']);
instance.UI.openElements(['leftPanel']);
},
};
window.ed.registerInterceptor(extractPagesInterceptor);